I don't think so. Oracle isn’t a consumer-facing company and doesn't really care about that sector. SWT and Swing will likely remain as ugly as they are for the next century, regardless of their popularity.
Microsoft, Google, and Apple have invested millions to polish their GUI solutions because that’s where their revenue comes from.
I don't think that will work. How many of us did contribute a simple patch to LibreOffice, Firefox, or GNOME?
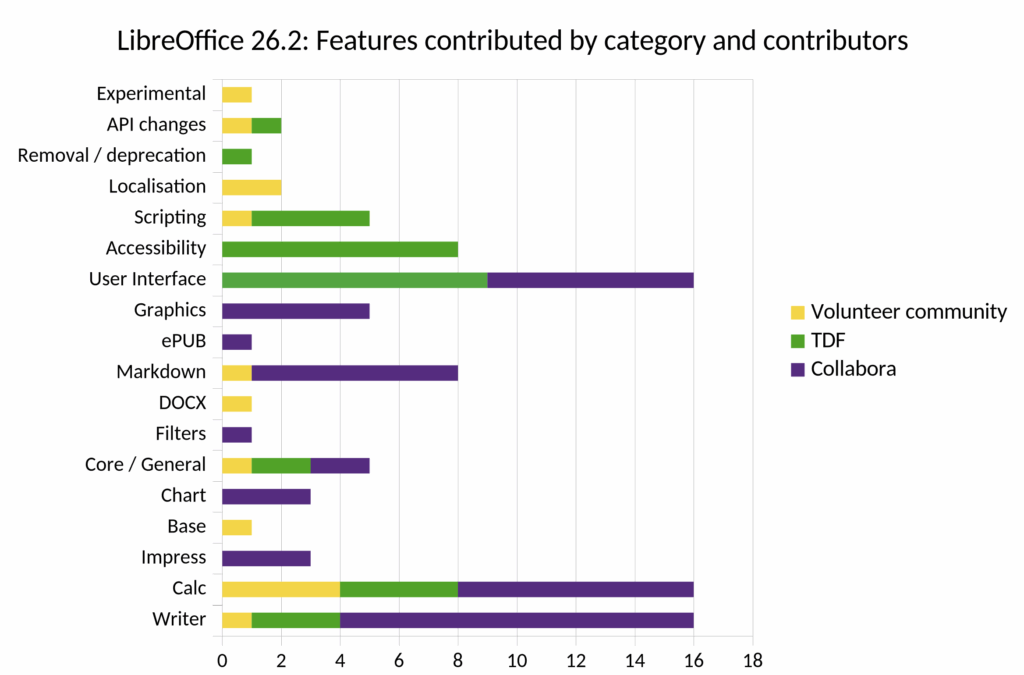
At least this statement doesn't hold for LibreOffice. Their Online version, including "simple" HTML/CSS components, was archived because of a lack of maintainers. For their main project, the vast majority of contributions in the last release were made by former ecosystem partners (Collabora) or TDF staff. Volunteers only did a fraction of the work [1].
The difference is that LibreOffice, Firefox, and GNOME are really really technically complicated.
Document file formats are a fucking nightmare, especially the Microsoft ones, and needing perfect compatibility with them spanning a generation is hell on earth.
Firefox is a similar scenario but for the web and decades of "it works on the dominant browser but the dominant browser refuses to follow the spec".
And GNOME is a matter of varying levels of direct hardware support/integration and app compatibility across basically the entire personal desktop computer and laptop eras.
Each of those has a compatibility scope that's absolutely massive.
Comparatively Tangled is a greenfield project with no compatibility requirements other than "support git" and "don't break compatibility with itself".
GitHub Actions doesn't have a lock file, so your repo is still prone to transitive attacks if the SHA-locked actions you use also happen to use other composite actions by tags, which could be compromised in the future.
Yes, it's maddening. Especially since it's a fair amount of effort to move to commit SHA pinning and establish a good maintenance/monitoring process around it; if I knew it would be adopted quickly, I could argue that people should just wait and accept temporary risk.
It would be cool if CI could inject a platform-wide lockfile into every remote download or lookup made by your scripts. So if you pull a container or git tag, the CI platform would automatically ensure that the exact digest downloaded is controlled by a lock file that you can inspect, check in, etc.
With free libre software, where freedom and liberty are about what the end user is empowered with actually, the software is mostly metonymic. Free software, free society, because there are free people in the middle of course.
Right, as I said elsewhere, maybe let's just let "open-source" have it.
"Open-source" can be "anything you can go out and grab a copy of and use" but doesn't give you much legal certainty about any of it, and reserve "free software" for the other, better thing.
But, free software lost it's way around GPLv3. From the end user's perspective, GPLv3 says that you can only use the software if it's either a cloud service, on hypothetical open firmware devices, or if you install it yourself.
AGPLv3 partially solves the issue by blocking people like Google from using it to build proprietary cloud services that take away their users' freedom. (It still doesn't solve the problem where providers use network effects to achieve the same end game.)
I don't understand this either. The GPL doesn't address end users and their use of software at all, to be technical. It only addresses what terms of copyright redistributors of GPLed software are allowed to apply in-turn to subsequent end users.
The point of the Free in free software was always to protect the users of the software, not the vendors or the redistributors. (This is why the license focuses on the redistributors -- the mechanisms of the license limit their rights in order to protect others' rights.)
The first sentence of the GNU manifesto says this, and a few sections later in the document elaborate on the point:
Note, in particular, footnote [1] which explains that its OK for distributors to ask for payment, but that it's never OK for users to have to ask for permission to use the software, and the section "Why I Must Write GNU".
Since then, software service monopolies became common, and all of the most end-user-hostile systems on earth rely heavily on the GNU system. At this point, we're paying for permission to use those services with our money, our data, our democracy, etc.
I certainly cannot give you permission to use any of the GPLed services that I have used, or that I've been paid to extend. Therefore, I say the free software movement has lost its way.
I see your point and I agree. It's just that when you say "GPLv3 says that you can only use the software if it's either a cloud service, hypothetical open firmware devices" that's a stretch and not really true. AIUI vendors can pre-install GPLv3 software as long as they let you actually then replace the software (i.e. no DRM or locked bootloader). The firmware can still be non-GPL and non-replaceable. You just can't use GPLv3 code in the non-replaceable bootloader or firmwares.
AFAIK you can use GPLv3 for non-replaceable stuff. The thing is only to allow the users to replace it IIF it's phisically possible to do so. If you make a device that boots from a ROM it's not a problem. If you sign your updates and keep your public key on a ROM and there is no way to boot anything else… there's a problem.
> From the end user's perspective, GPLv3 says that you can only use the software if it's either a cloud service, on hypothetical open firmware devices, or if you install it yourself.
The anti-tivo clause bans things like Apple pre-installing GPLv3 software on macs, but allows them to let you use exactly the same software as long as they do not give users access to the binary. AGPLv3 blocks both use cases, GPLv2 blocks neither.
On the spectrum of "things that take away user freedom", withholding the source code is bad. Withholding the source code, the binaries and physical access to the computer is obviously much worse! This latter business model is heavily subsidized by GPLv3.
The OSI's take on this is that an open source model can be modified through fine-tuning etc, even if you can't rebuild it from scratch.
The problem with requiring "build from scratch" for open source models is that the number of interesting models with training data that can be openly licensed is close to zero.
If you trained your model on an unlicensed scrape of the web you can't release the data under an open source license!
It is legal to train on copyrighted materials, provided they were obtained legally. Most companies also train their models using user interactions with previous iterations.
It is impossible to release this data publicly, let alone license it to a third party. However, I believe that at least the training code and the data processing pipeline could, and should, be released in order to claim a model is truly "open source."
That said, Allen AI actually released several models with the full datasets available. It is impressive how they pushed the models' performance despite training on a limited set of publicly available data. Kudos to them.
> The OSI's take on this is that an open source model can be modified through fine-tuning etc, even if you can't rebuild it from scratch.
By this definition almost any binary can be "open source" since hex editors exist. (Or more usefully, you can use ghidra et al. to do more interesting changes.) I know GPL has a very specific view of things, but I'd like to quote an excerpt that I think is generally applicable from https://www.gnu.org/licenses/gpl-3.0.html -
> The “source code” for a work means the preferred form of the work for making modifications to it. “Object code” means any non-source form of a work.
Which is why I'm fine with "open weights", because that's saying the object code is under an open license.
> The problem with requiring "build from scratch" for open source models is that the number of interesting models with training data that can be openly licensed is close to zero.
So? If the number of open source models is zero, then the number of open source models is zero.
I would personally disagree slightly with this take. Freely being able to use means IMHO, that this can be done for all applications in a legal (and ideally ethical) fashion. Regulation often requires to prove the quality or provenance of data. Open source has IMHO often a very libertarian view on things focusing on the rights of the user an not society in general.
To be fair, the initiators of the "Open Source" movement also co-opted a term that previously had a much more flexible meaning (and had been around for more than a decade at that point.) Just writing a document attributing specific criteria to a term does not grant one authority over the use of that term.
Ironically, the roots of the Open Source movement are a direct reponse to the Free Software movement largely because it was considered too ideological and unfriendly to corporate interests (i.e. monetization.)
> inventor of GIF didn't begin with a document clearly laying out what is and isn't to be called a "GIF”*
Neither did the inventors of AI. A third party published a document after corporations went with open weights = open source and a spoiler block in FOSS wanted all training data published.
> it's right to push back whenever a huge tech corporation tries to build goodwill by falsely using terms like "open source
I think it’s counterproductive. Most people only see a squabble, which makes any ensuing points from the open-source community seem silly. Those who care can continue using the more-precise language they choose to.
Put another way, there is a difference between using terms like cracker and fully spelling out cryptocurrency, and telling people who use hacker and crypto more loosely that they’re wrong. They aren’t wrong and that isn’t meaningful feedback. At the same time, the person using the precise language isn’t wrong either.
There's a big difference between correcting some random commenter on an internet forum and correcting Microsoft.
> think it’s counterproductive. Most people only see a squabble, which makes any ensuing points from the open-source community seem silly.
Only to people that truly don't care whether something's open source. In which case, Microsoft using the term (correctly or incorrectly) won't change their perception.
But the people who do care won't like to be mislead by Microsoft. There's a reason the term is right in the headline: people respond to it.
I wish I had time to come up with a better example, but it's like if a AAA game company says they've released "native Linux build," but really they're just packaging the Windows build with Wine.
99% of people won't care, neither about the news nor the deception. But for that last 1%, any goodwill garnered with the headline would be gone, and the game company are the ones who look foolish, not the people calling them out.
I've been pronouncing both of them as /dʒis/ like hiss and not /dʒɪz/. I however am not a native english speaker of English. I wonder if native speakers gravitate towards the z more?
I would end both with the S sound, but I'm operating under the assumption that the person I was replying to either pronounces their Ss as Zs or can't tell the difference between the S and Z sounds.
Because the other assumption I could have gone with is the less charitable take that they know GIS with a soft G doesn't sound like jizz, but they were just looking for a crude way to mock the soft G.
Same way I pronounce my first name btw ;) but I think of "gif" as "gift" and this is probably the subconscious association people make without realizing it.
Which is why I find it fun to bring up that in Old English "gift" hadn't yet picked up the "t" and was spelled "gif", but in Old English "g" was most commonly "HY". I like the Old English pronunciation of "gif" as "HYEEF", which is a "compromise" position that often makes some of both soft-g and hard-g "gif" pronunciation fans angry.
I sometimes just pick the opposite of whatever everyone agreed to just for fun. I do the same when people cry about vim or emacs since I have used both. ;)
Some men just want to watch the world burn. At least it's mostly harmless fun anyway. It's even funnier when they bring up how my name is pronounced in defense of "jiff" and I tell them, so you're calling me the expert in "Gi" pronunciation then? :)
Basically hallucinations are false external things, and delusions false internal things. You hallucinate a pink elephant, you delude yourself into thinking trump won 2020.
Devils advocate here: I can give you a binary of my open source MIT code and never phone you the code. The code is still MIT licensed, and open source. You just have no access to it.
That said, I entirely agree that MS is misrepresenting their openness here, which isn’t in the least surprising.
I don't disagree, but it is perfectly acceptable per the MIT license, which is an OSI approved license. MIT doesn't require source distribution with the binary (which is why from the developer perspective, it's a more "permissive" license)
The license describes what users are allowed to do with the source code, it doesn’t (and shouldn’t) define what a creator has to do to make the source code open.
Then it sounds like you're philosophically opposed to copyleft license like GPL. That's ok, we can agree to (in my case vehemently) disagree, but your philosophy is inconsistent with the commonly accepted definition of "open source" such as OSI's OSD[1][2]
I think you completely misunderstand me. I don’t have any opinion on GPL, but in the links you shared, even OSI considers the license to be separate from the definition of open source “Open source licenses are licenses that comply with the Open Source Definition”. You can use a license that open source projects use (ie MIT), and still keep the source closed, or you can write one that puts obligations on you if you want. In fact, you can use or write pretty much any license you want if you own the copyright.
In their defense, most everyone else does the same thing. They still shouldn't do it, but at least they're not the trendsetter here (though they are contributing to the ongoing problem)
Open weights is not exactly right either because we do get source of the software that uses those open weights.
Maybe open inference?
But we often also get source code for fine tunning the model.
So maybe it's closer to open source than to anything else?
Isn't it a bit like not calling a game open source because engine tooling used to made it isn't open source and they didn't publish .psd files with asset designs?
I'm genuinely torn on this one; I get technically why not, but why I think I have no problem with it is the wishy-washiness of "open source" generally.
As I teach this stuff to people newer to this tech, it's probably just easier and more helpful to refer to the wide array of "stuff you can just download and use yourself" as "open-source" and then after that, go deeper and talk about why Stallman was right, how "Free Software" was first. etc.
I mean, you have "AI" which means just about anything in marketing speak, "Agentic" is kind of becoming similar, hopefully they don't goof that one too badly, would be nice to know what you are trying to sell me. Used to be "Cloud" meant storage not just hosting (I guess it still does).
Then there's "Smart" in front of Car, Phone, TV, and so on... Meaning different things.
I do think "Open Weight" should be more commonly used. There's definitely communities that spring up that build the training infrastructure and inference infrastructure around open models on the other hand.
> “This means a future of abundance. A future where there is no poverty, where people can have whatever they want in terms of goods and services.” – Elon Musk
> “I think we see a path now where the world gets much more abundant and much better every year.” – Sam Altman
Ahh, thank you. The lipstick they put on the pig that is Elon's dream of an Afrikaaner enclave on Mars where the 1% can finally extricate themselves from the rest of the species.
RFC 1855, Netiquette Guidelines[1], specifies underscore for underlining. However, it says asterisks are for emphasis, not bold, per se. They just happened to (often?) display as bold because italics in terminals weren't a common thing. For the same reason, using /'s for italics didn't make much sense except maybe in word processors. I also suspect underscore become conflated with asterisk because some people preferred using the former for emphasis--people weren't usually trying to adhere to professional styling guides, and some people may have preferred underlining to impart emphasis, or just got into the habit without thinking about it.
I don't know how well RFC 1855 reflected common practice, though. It might be worthwhile to check the rendering code in clients like tin and mutt.
Since this seems to boil down to personal choice, has anyone considered a customisable alternative? Like a frontmatter that declares which character is bold, which is italic. You could easily convert between them according to local preference, much like tabs/spaces.
I know this is a throwaway joke, but I was interested anyway...
According to my own local Markdown formatters, the answer would be both "usr" and "bin", with the surrounding slashes removed, but the internal slash remaining. In other words:
usr/bin
(but underlined instead of italic!)
Of course, this problem is nothing new since a filename might easily be named `_my_file_`.
So this is actually competing in the typesetting space, likely with Typst. Both aim to become a simpler alternative to LaTeX without that pain in the ass.
I think they are missing an opportunity to fix a poor design decision in Markdown. Instead of **bold** and *italic*, it should be *bold* and _italic_. That extra asterisk really makes it inconvenient to edit Markdown on a phone or tablet. I hope they fix that in v3.
Modification Ban: The User has no right to change, modify, decompile, disassemble or create derivative works based on the Program.
Distribution Ban: The User has no right to distribute the Program without the prior written permission of the Licensor.
I can't afford a free license. I have no sponsors and have been unemployed for a year. It's rare for a free-source project to succeed, so I decided not to use a free license initially.
I find this response a little odd. Absolutely respect the work you’ve put in, but explaining that it doesn’t have a free license because you’ve been unemployed is just bad marketing.
“It doesn’t have a free license because I believe in the product and think it stands out enough to warrant people paying for it” is probably the route you want to go.
I once heard that the USB naming is misleading by design so that vendors could still sell older generations accessories they had in stock. The USB-IF just rebrands the old ones to make them sound current.
Imagine the following naming:
USB 3.0 / USB 3.1 Gen 1 / USB 3.2 Gen 1 -> USB 3 5Gbps
USB 3.1 / USB 3.1 Gen 2 / USB 3.2 Gen 2 -> USB 3 10Gbps
USB 3.2 Gen 2x2 -> USB 3 20Gbps
Isn't that much clearer? I think USB 4 is finally going to the right direction.
> I think USB 4 is finally going to the right direction.
USB 4 is actually going into an even worse direction. USB 4 = Thunderbolt 4, except everything is optional. e.g. USB 4 might not even support DP Alt mode. Thunderbolt 4 always will.
That is exactly how the USB IF has been branding it for consumer use. They explicitly tell[0] implementers to not call it "USB 3.2 Gen2x2", but "USB 20Gbps".
The problem is just that the manufacturers and the tech press keep ignoring it...
Which is why I honestly believe they should have fixed this in the design stage itself. Post-facto reframing/renaming never seems to go well.
Especially once the mass produced cheap stuff starts being churned out, and there's no cost incentive to go back and fix wrong messaging. USB-IF constantly drops the ball around this ngl, feels like they're a pure scientific community that doesn't think about consumer adoption and UX.
j5create USB4 8K Slim Hub - 8K60/4K144 HDMI, 1 x USB-C 10Gbps with PD charging, 1 x USB-C 10Gbps, 2 x USB-A 10Gbps | Compatible with MacBook, Windows Laptops (JCH453)
I bought it because unlike many other USB hubs, the host connection is USB4 / Thunderbolt 4, instead of just USB3 for the host connection.
> Ultimate Connectivity: JCH453 combines the latest USB4 controller with Thunderbolt 4 and USB compatibility, ensuring seamless connectivity with various devices. Experience the power of multiple ports in one hub.
> A USB4® multi-port hub incorporates the latest USB4® controller offering compatibility with Thunderbolt™ 4 and older USB™ specifications.
> With up to 40Gbps of throughput, dynamic data, and display bandwidth allocation for efficient display data flow, you can easily create a high-definition monitor setup.
I think this practice is rather blatantly what you say. The same thing with HDMI forum folding HDMI 2.0 into HDMI 2.1. They made the new 2.1 features optional, therefore manufacturers were able to call their 2.0 devices 2.1 without actually supporting the 2.1 features. AMD has been recently doing similar things, releasing “new” generation of mobile processors where half of them are just rebrands of the older generation.
{kind=link}
Microsoft, Google, and Apple have invested millions to polish their GUI solutions because that’s where their revenue comes from.
reply