> would be nice to have a place that have a list of typical models/ hardware listed with it's common config parameters and memory usage
https://www.localscore.ai from Mozilla Builders was supposed to be this, but there are not enough users I guess, I didn't find any Qwen 3.5 entries yet
That's a very dishonest take, as I'm sure you know that Sommerzeit proponents have reasons other than "summer sounds better than winter".
For example most people just wake up and go to work in the morning, but in the evening they meet friends, BBQ, hike/run through nature, do sports etc., and prefer doing those activities while it's bright outside.
My "very dishonest take" is the result of the polls after the EU parliament voted to stop the time change.
The question in these polls had been which time the person would prefer. A big majority in Germany chose "summer time". So without any reasons given/discussed/researched the preference is summer time.
Of course there are proponents with reasons for or against this or that time but this doesn't matter as the majority does not decide by reasons.
My point is that alone the naming the time "summer" or "winter" influences the preference to a big extent.
What's dishonest about your take is your strawman interpretation of the poll results. Just because you disagree with the majority of people does not mean they simply misunderstand the question and think
"hurr durr summer better than winter, me choosey summer"
Well, at least thats the way I would have responded to the question when interviewed. Maybe I'm dumber or more mindless than the average german.
There were say some 100s of people called by phone, asked a lot of questions about a lot of topics, one of them is "which do you prefer: summer or winter time" - I would have said summer (without thinking to much) because I like the long summer evenings too.
That has nothing to do with misunderstanding the question.
It is of course possible that the average interviewee is well prepared or thinks long and hard before answering without letting the wording influence their answer.
But you should at least consider the possibility that also the german naming (summer/winter) could influence some people (like me) in their answers.
(I think the wording can have a big influence (maybe because of my linguistic background) but you are free to disagree)
What stops you from going to work one hour early, so you get off earlier as well? Most employers these days allow flexible working hours.
And if we are permanently moving our clocks to advance by an hour, why stop at just one hour? Why not have +2h or +3h so we get even more brighter evenings.
"Most employers" definitely don't allow flexible working hours. You have to be in specific sectors – basically just "modern" tech companies – to have that privilege. And that is a very tiny slice of the working population.
Because most people don’t have that degree of flexibility. When I was commuting I’d have been happy to have double DST or whatever you want to call it.
So far both projects are quite similar… the only major difference being the search index. Onyx uses vespa.ai for BM25 and vector search, I decided to go down the Postgres-only route.
I'm the author of another option (https://github.com/mickael-kerjean/filestash) which has a S3 gateway that expose itself as a S3 server but is just a proxy that forward your S3 call onto anything else like SFTP, local FS, FTP, NFS, SMB, IPFS, Sharepoint, Azure, git repo, Dropbox, Google Drive, another S3, ... it's entirely stateless and act as a proxy translating S3 call onto whatever you have connected in the other end
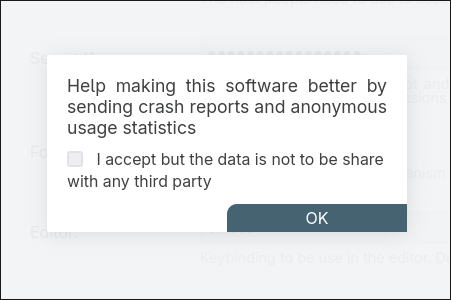
I clicked settings, this appeared, clicking away hid it but now I cant see any setting for it.
The nasty way of reading that popup, my first way of reading it, was that filestash sends crash reports and usage data, and I have the option to have it not be shared with third parties, but that it is always sent, and it defaults to sharing with third parties. The OK is always consenting to share crash reports and usage.
I'm not sure if it's actually operating that way, but if it's not the language should probably be
Help make this software better by sending crash reports and anonymous usage statistics.
Your data is never shared with a third party.
[ ] Send crash reports & anonymous usage data.
[ OK ]
Hi, I really like how the software is setup, but there is almost no documentation. This makes it hard to setup. I want to run it with the local storage plugin, but it keeps using / as the storage location and I want it to use /data which I volume mount. Maybe think about improving the documentation :)
I was looking at running [versitygw](https://github.com/versity/versitygw) but filestash looks pretty sweet! Any chance you're familiar with Versity and how the S3 proxy may differ?
I did a project with Monash university who were using Versity on their storage to handle multi tiers storage on their 12PB cluster, with glacier like capabilities on tape storage with a robot picking up data on their tape backup and a hot storage tier for better access performance, lifecycle rules to move data from hot storage to cold, etc.... The underlying storage was all Versity and they had Filestash working on top, effectively we did some custom plugins so you could recall the data on their own selfhosted glacier while using it through the frontend so their user had a Dropbox like experience. Depending on what you want to do they can be very much complimentary
rustfs have promise, supports a lot of features, even allows to bring your own secret/access keys (if you want to migrate without changing creds on clients) but it's very much still in-development; and they have already prepared for bait-and-switch in code ( https://github.com/rustfs/rustfs/blob/main/rustfs/src/licens... )
Ceph is closest feature wise to actual S3 feature-set wise but it's a lot to setup. It pretty much wants few local servers, you can replicate to another site but each site on its own is pretty latency sensitive between storage servers. It also offers many other features aside, as S3 is just built on top of their object store that can be also used for VM storage or even FUSE-compatible FS
Garage is great but it is very much "just to store stuff", it lacks features on both S3 side (S3 have a bunch of advanced ACLs many of the alternatives don't support, and stuff for HTTP headers too) and management side (stuff like "allow access key to access only certain path on the bucket is impossible for example). Also the clustering feature is very WAN-aware, unlike ceph where you pretty much have to have all your storage servers in same rack if you want a single site to have replication.
Not sure what you mean about Ceph wanting to be in a single rack.
I run Ceph at work. We have some clusters spanning 20 racks in a network fabric that has over 100 racks.
In a typical Leaf-Spine network architecture, you can easily have sub 100 microsecond network latency which would translate to sub millisecond Ceph latencies.
We have one site that is Leaf-Spine-SuperSpine, and the difference in network latency is barely measurable between machines in the same network pod and between different network pods.
Ceph has synchronous replication, writes have to be acked by all replicas before the client gets an ack. Fundamentally, the latency of ceph is at least the latency between the OSDs. This is a tradeoff ceph makes for strong consistency.
I know. We run it for near a decade now. I mentioned it because a lot of uses for minio are pretty small.
I had 2 servers at home running their builtin site replication and it was super easy setup that would take far more of both hardware and work to replicate to ceph so while ceph might be theoretically fitting feature list, realisticially it isn't an option.
The Ceph way of doing asynchronous replication would be to run separate clusters and ship incremental snapshots between them. I don't know if anyone's programmed the automation for that, but it's definitely doable. For S3 only, radosgw has it's own async replication thing.
I don't think this is a problem. The CLA is there to avoid future legal disputes. It prevents contributors from initiating IP lawsuits later on, which could cause significantly more trouble for the project.
Hypothetically, isn't one of the "legal disputes" that's avoided is if the projects relicenses to a closed-source model without compensating contributors, the contributors can't sue because the copyright of the contributions no longer belongs to be them?
Contributors cannot initiate IP lawsuits if they've contributed under Apache 2.0. CLAs are to avoid legal disputes when changing the license to commercial closed source.
Would be cool to understand the tradeoffs of the various block storage implementations.
I'm using seaweedfs for a single-machine S3 compatible storage, and it works great. Though I'm missing out on a lot of administrative nice-to-haves (like, easy access controls and a good understanding of capacity vs usage, error rates and so on... this could be a pebcak issue though).
Ceph I have also used and seems to care a lot more about being distributed. If you have less than 4 hosts for storage it feels like it scoffs at you when setting up. I was also unable to get it to perform amazingly, though to be fair I was doing it via K8S/Rook atop the Flannel CNI, which is an easy to use CNI for toy deployments, not performance critical systems - so that could be my bad. I would trust a ceph deployment with data integrity though, it just gives me that feel of "whomever worked on this, really understood distributed systems".. but, I can't put that feeling into any concrete data.
Apart from Minio, we tried Garage and Ceph. I think there's definitely a need for something that interfaces using S3 API but is just a simple file system underneath, for local, testing and small scale deployments. Not sure that exists? Of course a lot of stuff is being bolted onto S3 and it's not as simple as it initially claimed to be.
SeaweedFS's new `weed mini` command[0] does a great job at that. Previously our most flakey tests in CI were due to MinIO sometimes not starting up properly, but with `weed mini` that was completely resolved.
Minio started like that but they migrated away from it. It's just hard to keep it up once you start implementing advanced S3 features (versioning/legal hold, metadata etc.) and storage features (replication/erasure coding)
There's plenty of middle ground between "just expose underlying FS as objects, can't support many S3 operations well" and "it's a single node not a distributed storage system".
For my personal use, asynchronous remote backup is plenty for durability, a Bee-Link ME Mini with 6x4TB NVMe is plenty of space for any bucket I care to have, and I'd love to have an S3 server that doesn't even attempt to be distributed.
Yes I'm looking for exactly that and unfortunately haven't found a solution.
Tried garage, but they require running a proxy for CORS, which makes signed browser uploads a practical impossibility for the development machine. I had no idea that such a simple popular scenario is in fact too exotic.
From what I can gather, S3Proxy[1] can do this, but relies on a Java library that's no longer maintained[2], so not really much better.
I too think it would be great with a simple project that can serve S3 from filesystem, for local deployments that doesn't need balls to the walls performance.
The problem with that approach is that S3 object names are not compatible with POSIX file names. They can contain characters that are not valid on a filesystem, or have special meaning (like "/")
A simple litmus test I like to do with S3 storages is to create two objects, one called "foo" and one called "foo/bar". If the S3 uses a filesystem as backend, only the first of those can be created
I believe the Minio developers are aware of the alternatives, having only their own commercial solution listed as alternatives might be a deliberate decision. But you can try merging the PR, there's nothing wrong with it
Had great experience with garage for an easy to setup distributed s3 cluster for home lab use (connecting a bunch of labs run by friends in a shared cluster via tailscale/headscale). They offer a "eventual consistency" mode (consistency_mode = dangerous is the setting, so perhaps don't use it for your 7-nines SaaS offering) where your local s3 node will happily accept (and quickly process) requests and it will then duplicate it to other servers later.
Overall great philosophy (target at self-hosting / independence) and clear and easy maintenance, not doing anything fancy, easy to understand architecture and design / operation instructions.
I don't think this is a problem. The CLA is there to avoid future legal disputes. It prevents contributors from initiating IP lawsuits later on, which could cause significantly more trouble for the project.
From my experience, Garage is the best replacement to replace MinIO *in a dev environment*. It provides a pretty good CLI that makes automatic setup easier than MinIO. However in a production environment, I guess Ceph is still the best because of how prominent it is.
Yep I know, I had to build a proxy for s3 which supports custom pre-signed URLs.
In my case it was worth it because my team needs to verify uploaded content for security reasons. But for most cases I guess that you can't really bother deploying a proxy just for CORS.
Garage does actually support CORS (via PutBucketCORS). If there is anything specific missing, would you be wiling to open an issue on our issue tracker so that we can track it as a feature request?
Although the doc only mentions CORS [1] on an "exposing website page" which is not exactly related; also the mention strongly suggests using reverse proxy for CORS [1] which is an overkill and perhaps not needed if supported natively?
Also googling the question only points out to the same reverse proxy page.
Now that I know about PutBucketCORS it's perfectly clear but perhaps it's not easily discoverable.
I am willing to write a cookbook article on signed browser uploads once I figure out all the details.
But also many countries have ID cards with a secure element type of chip, certificates and NFC and when a website asks for your identity you hold the ID to your phone and enter a PIN.
> Smooth offers a “self” proxy that creates a secure tunnel and routes all browser traffic through your machine’s IP address
Can you confirm that you only route the traffic of the one user who owns the machine though the proxy? Or do you use it as residential proxy for other users as well?
Some European companies migrate their dependencies from US clouds to European ones. Turso is registered in Delaware. Bunny HQ is in Slovenia. Different data related policies apply.
Title can be misleading, as KDE still works on non-systemd systems that use other login managers, as discussed here: https://hackernews.hn/item?id=46870751
{kind=link}
reply