Nothing that was shown is beyond the capabilities of robots from over a decade ago like Asimo (e.g. https://www.youtube.com/watch?v=am1csALyEzE). It was a cool demo and beyond hobbyist capabilities, but realistically achievable by a commercial lab without having to fake it.
No, remote operators are never in control of the vehicles. They give the computer hints about how to handle situations it's unable to resolve for itself, but the computer is ultimately still responsible for driving and maintaining the safety invariants.
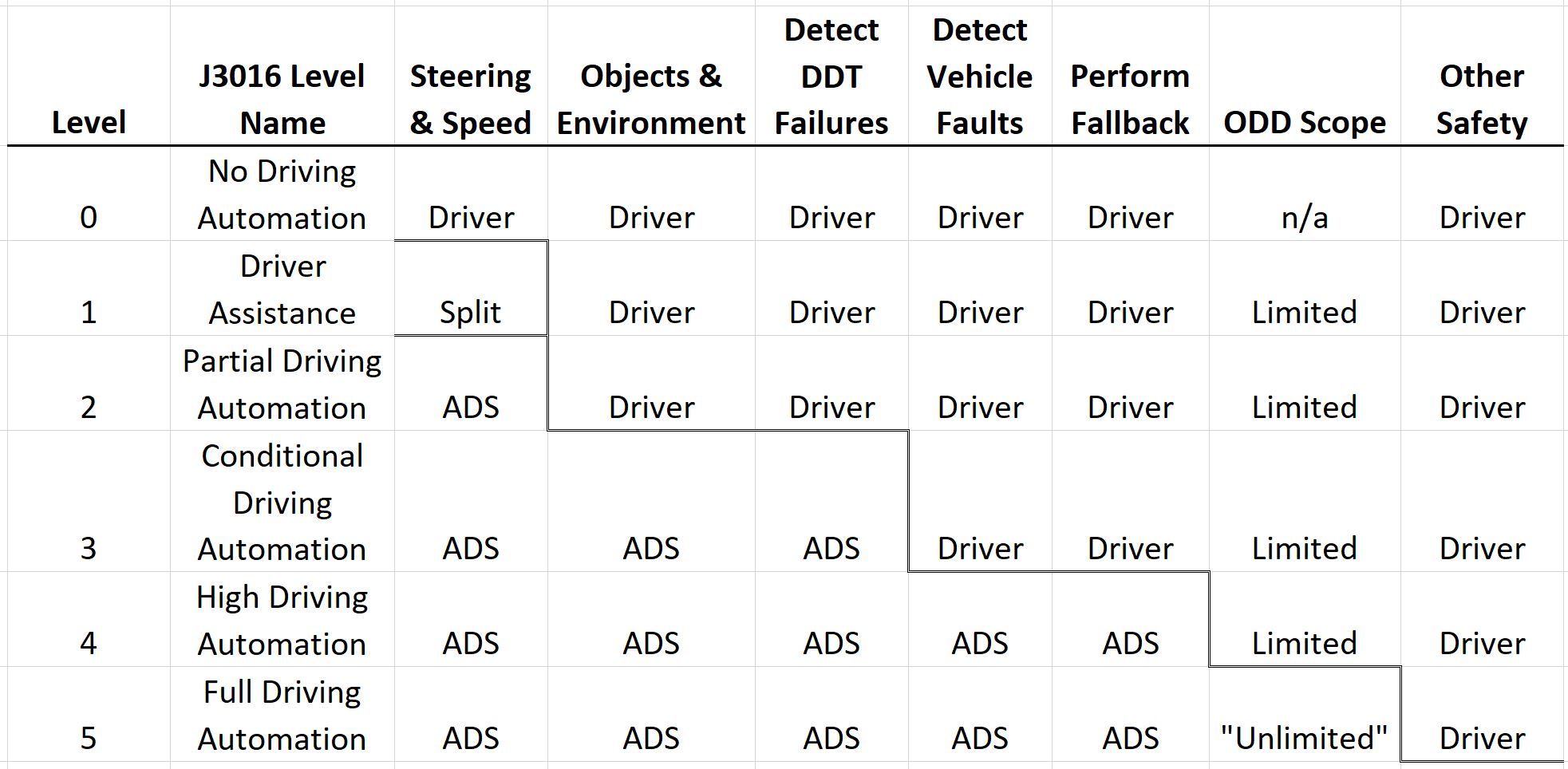
This is fundamentally different from FSD, where the human is always responsible for driving and maintaining the safety invariants.
It entails a completely different division of responsibilities and safety profile. Specifically, it's one of the critical differences between SAE levels 2/3 and level 4:
To give an analogy, let's say you use a credit card. A machine processes the payment most of the time, but occasionally something looks suspicious, so it denies the payment and sends a message to a human (you) asking whether the next payment should be allowed. Do you consider yourself to be a "driver" in this system?
If so, imagine a system where all payments flash by onscreen for a human that's tasked with stopping erroneous approvals in realtime. Are humans doing the essentially the same job in this system such that both roles are "drivers"?
Vehicles are dominated by the production costs of producing anything. You save surprisingly little producing smaller vehicles because the expensive bits are all the things you don't majorly save on like the production lines, the battery, the mechanicals, the wiring, the electronics, etc. Nicer interiors, paint options, and other consumer upgrades have extremely low marginal costs. They're pure profit for the manufacturer.
It's strictly more expensive if you're limited to say, the typical NHTSA autonomous vehicle production limit of 2,500 vehicles per year.
If you go down to basic physical material costs, Surface area of car, Metal cost, Glass cost etc, are the things which will determine car price in long run, So car which is weighting let's say 25% percent less can be be built cheaper compared to car weighting more. Less doors, less glass use, less paint, less material, less battery needed for same amount of distance, which brings down to cost.
Ok, lets think of it other way, all things equal, if you are tasked with cutting costs of vehicle without cutting back things which makes your brand unique, and without reducing margin or running on loss how will you do it?
You make vehicle simpler, with less expensive parts. That's how hardware design works.
Cutting back on quality or software expense is not a option for Tesla as that will make Tesla equal to any other Chinese EV brand.
Raw material is less than half of the price of a vehicle, right? Assuming it’s 50%, a 25% smaller car would save 12.5%.
I would be surprised if raw material is even 50% of the cost.
Just look at traditional USA automakers and why they are scaling up their vehicles. Bigger vehicles can justify bigger prices thus bigger margins. Even if the manufacturing price is not that much different.
The scene was around and doing interesting things long after 2005, like Floppus / Ben factoring the TI RSA signing keys in 2009 [0], Quigibo / Kevin writing Axe, and SirCmpwn / Drew with KnightOS. The TI-84+ wasn't even released until 2004, and that was probably the biggest hardware for the broader community. It was a fun time to be involved and get a C&D.
> List them. I am not aware of any well defined parts of the C standard where GCC and Clang disagree in implementation.
Perhaps it's not "well defined" enough for you, but one example I've been stamping out recently is whether compilers will combine subexpressions across expression boundaries. For example, if you have z = x + y; a = b * z; will the compiler optimize across the semicolon to produce an fma? GCC does it aggressively, while Clang broadly will not (though it can happen in the LLVM backend).
This is behavior is mostly just unspecified, at least for C++ (not sure about C).
I'm aware of some efforts to bring deterministic floating point operations into the C++ standard, but AFAIK there are no publicly available papers yet.
P3375R0 is public now [0], with a couple implementations available [1], [2].
Subexpression combining has more general implications that are usually worked around with gratuitous volatile abuse or magical incantations to construct compiler optimization barriers. Floating point is simply the most straightforward example where it leads to an observable change in behavior.
You're very right that this goes above and beyond anything the C standard specifies aside from stating that the end result should be the same as if the expressions were evaluated separately (unless you have -ffast-math enabled which makes GCC non-conformant in this regard).
If the end result of the calculation differ (and remember that implementations may not always use ieee floats) then you can call it a bug in whatever compiler has that difference.
I have no idea how C++ defines this part of its standard but from experience it's likely that it's different in some more or less subtle way which might explain why this is okay. But in the realm of C, without -ffast-math, arithmetic operations on floats can be implemented in any way you can imagine (including having them output to a display in a room full of people with abaci and then interpreting the results of a hand-written sheet returned from said room of people) as long as the observable behaviour is as expected of the semantics.
If this transformation as you describe changes the observable behaviour had it not been applied, then that's just a compiler bug.
This usually means that an operation such as:
double a = x / n;
double b = y / n;
double c = z / n;
printf("%f, %f, %f\n", a, b, c);
Cannot be implemented by a compiler as:
double tmp = 1 / n;
double a = x * tmp;
double b = y * tmp;
double c = z * tmp;
printf("%f, %f, %f\n", a, b, c);
Unless in both cases the same exact value is guaranteed to be printed for all a, b, c, and n.
No, it's not a compiler bug or even necessarily an unwelcome optimization. It's a more precise answer than the original two expressions would have produced and precision is ultimately implementation defined. The only thing you can really say is that it's not strictly conforming in the standards sense, which is true of all FP.
I read up a bit more on floating point handling in C99 onwards (don't know about C89, I misplaced my copy of the standard) and expressions are allowed to be contracted unless disabled with the FP_CONTRACT pragma. So again, this is entirely within the bounds of what the C standard explicitly allows and as such if you need stronger guarantees about the results of floating point operations you should disable expression contraction with the pragma in which case, (from further reading) assuming __STDC_IEC_559__ is defined, the compiler should strictly conform to the relevant annex.
Anyone who regularly works with floating point in C and expects precision guarantees should therefore read that relevant portion of the standard.
"Strictly conforming" has a specific meaning in the standard, including that all observable outputs of a program should not depend on implementation defined behavior like the precision of floating point computations.
It can be controlled through compiler options like -ffp-contract
In my opinion every team finds fp options for their compiler through hard time bug fixing :)
and I am still in shock that many game projects still ship with fast math enabled.
Does this mean you get benefits (like free housing, healthcare, and money to buy food with) if you earn less than 105k/year? Or what does low income threshold mean here
It's one criteria for eligibility for social benefits that can include being able to live in certain kinds of public housing. Usually there's a lot more criteria that go into it, but income is a fairly major one.
It means not using explicit functions, just writing the same code as little inline blocks inside the main function because it allows you to see all the things that would be hidden if all the code wasn't immediately visible.
To the other point though, the quality of compiler inlining heuristics is a bit of a white lie. The compiler doesn't make optimal choices, but very few people care enough to notice the difference. V8 used a strategy of considering the entire source code function length (including comments) in inlining decisions for many years, despite the obvious drawbacks.
Well there's also compiler directives other than `inline`, like msvc's `__inline` and `__forceinline` (which probably also have an equivalent in gcc or clang), so personally I don't think you need to make the tradeoff between readability and reusability while avoiding function calls. Not to mention C++ constevals and C-style macros, though consteval didn't exist in 2007
__forceinline is purely a suggestion to the compiler, not a requirement. Carmack's point isn't about optimizing the costs of function calls though. It's about the benefits to code quality by having everything locally visible to the developer.
It's an interesting view because I find neatly compartmentalized functions easier to read and less error prone, though he does point out that copying chunks of code such as vector operations can lead to bugs when you forget to change some variable. I guess it depends on the function. Something like
Vector c = dotProduct(a, b);
is readable enough and doesn't warrant inlining, I think. There's nothing about `dotProduct` that I would expect to have any side effects, especially if its prototype looks like:
Vector dotProduct(Vector const& a, Vector const& b) const;
There are embedded Java systems. I hope you never have to work with any.
In general, embedded systems suffer from severe lack of tool developer attention. People standardize on the very few things that reliably work like C, C++, and printf debugging because they don't have the bandwidth for anything more. Anything outside the beaten track has a high chance of running into showstopping bugs halfway through a project and embedded teams are already struggling to find developer time in the typical situation of 1-10 people maintaining 1M+ LOC codebases.
Rust is the first real alternative to C and C++ in decades because it's actually trying to address the ecosystem issues.
Not even "printf" is included in any standard, I'm afraid. Arm's Keil MDK toolchain has an typical implemetation of baremetal C/C++ environment called microlib, but unfortunately it doesn't support RTOS because of the missing of re-entrancy, so you have to provide or use a third-party alternative.
I'm not stopping you from trying to put your theories to the test and I'm not saying the current reality is good. However, I think you'd be surprised how complex some of these systems are. An automotive system like the article is describing is a distributed realtime system of anywhere from dozens to hundreds of networked processors built without traditional operating system support. It's frankly a miracle they work at all.
While I don't work in the automotive field, I've worked on adjacent-esque distributed systems with some of the shared protocols (e.g., CANopen). Part of my lament here is that almost no effort has been put into anything other than running C and C++ on embedded systems. While hard real-time systems are a thing, other pieces have often still been implemented in C and C++, which is a shame. And it's also a shame that more effort hasn't been put into realtime garbage collectors, especially in this age of multicore embedded CPUs.
I fully agree that it's a miracle any of the existing stuff works at all. I honestly have no idea how C and C++ developers make it work. Despite being the oldest and most used languages, the tooling is atrocious.
C++ is the most direct comparison. Neither GCC nor Clang have LTS releases. MSVC does via Visual Studio, but I've never seen anyone list it as a benefit vs the other two. What advantage does LTS have for compiler toolchains if no one seems to want it?
And those ancient, niche toolchains are horribly buggy as a rule. For example, a certain Santa Barbara based vendor ships a high integrity compiler that you can crash with entirely normal standards compliant C/C++.
Would it make you feel better if I told you that these kinds of offerings usually also don't offer modern validation tools like sanitizers? They expect people to just wing it with whatever the proprietary IDE happens to give them.
A big part of the job of safety critical development is knowing the difference between box checking best practices/regulations and building actually safe systems so you can do both.
I would assume the solution is to run your code through multiple compilers/toolchains - in dev, CI can run the certified compiler to make sure your code stays compatible with it, but also through modern clang/gcc with every linter and static analysis tool you can think of. Then for the "official" prod builds you use the certified compiler. Automated testing should probably use both, and even compare the behavior of binaries from each chain to look out for bugs that only exist in one. That way you get most of the benefits of both worlds (not all, since you can only write code that all compilers can handle).
That's a common partial solution, but it's not complete. For example, it essentially requires you to be able to observe all safety-relevant behaviors of the code in both compilers. This is a much more comprehensive degree of validation than almost any system actually achieves. You also run into issues where the behaviors you're observing (e.g. low bits in floating point results) depend on intimate details of codegen that aren't identical between compilers.
The complete solution depends on the application and the integrity level. It's not one size fits all, but rather about producing documentation showing you've considered various failure modes and developed mitigations for them (or otherwise accept the risk). Sometimes that's binary analysis of the compiled output to ensure it meets some formal model, sometimes that's a formally proven, decent compiler like concert, and so on.
An additional wrinkle is that the business model for high integrity compilers can also be a huge obstacle here. Some charge seats by how many people have modified the code that's running through the compiler. These aren't cheap licenses either, so companies have a large incentive not to use methodologies that require many eyes making all bugs shallow. There are also issues running these compilers in CI. They might require online license verification on every file, for example, or not allow ephemeral licensing at all.
It isn’t. The idea is to quantify the risk. A buggy toolchain is okay if the bugs are known and you can demonstrate how you’re mitigating them. All software has bugs, you cannot rely on the idea of bug free software to ensure safety, you must have a process that is robust in the face of problems.
I don’t disagree that in general, reducing the number of bugs is a good goal, but there’s always a limit to how far you go. It’s not like every line is formally proven, for example. Just because you can use a specific technique doesn’t mean that you must.
But also I don’t work directly in these industries and so maybe my impression of this aspect of their processes is incorrect.
I actually think far more of these safety of life standards should require formal proof.
IMNSHO the standards were set so low so that C++ could clamber over the low bar, and it's a happy consequence in some sense that Rust has no trouble clearing it, but the bar should be raised considerably instead. Software crucial to the safe operation of an airliner ought to be proven correct, not just slapped together in any of the general purpose languages, including Rust and then subject to a bit more process than for a web app.
That would explode the costs for marginal safety improvements. I think the same effort spent on better requirement engineering would yield more payoff.
Because proving correctness for complex software is difficult and very few people have relevant experience. So it is both labor intensive and you need to pay high wages. I believe the safety improvements are marginal because of my experience in safety critical development. Almost all the bugs we did not find by testing turned out to be problems with the requirements that led to interoperability issues. Proving the correct implementation of wrong requirements would not have helped.
Its not so much about ensuring the best tool chain is used, but rather about setting the lowest bound of quality. By being slow moving it avoids the potential for temporary regressions.
It is also ass-covering by demonstrating you followed "industry standard procedure". If you do something different, even if it is quantifiably better, it might make for a stressful deposition explaining why the worse but standard approach wasn't used instead.
{kind=link}
reply